
These are uncertain times, so let’s talk about uncertainty. In particular, I would like to focus on how we quantify uncertainty, focusing on the failings of our most common quantifier of uncertainty (the standard deviation) and singing the praises of alternative entropic measures of uncertainty. This not only impacts how we think about uncertainty, but also how we understand the information-theoretic process of learning itself. I’ll come back to this at the end.
So, what is uncertainty, and how do we quantify it?
One of the most common ways to define and quantify uncertainty is through the standard deviation or root mean squared error. For an arbitrary classical probability distribution 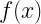
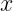



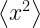


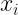


Does this definition of uncertainty seem clunky and non-amenable to calculation? Fear not, enter our humble friend, the Gaussian distribution.

The Gaussian distribution (also known as the normal distribution, especially in the social sciences) is perfectly amenable to the standard deviation as a measure of its uncertainty. First and foremost, the standard deviation has a clear physical interpretation; at one standard deviation 
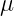

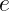
Now by incredible coincidence, the Gaussian distribution appears in two vastly different contexts in Physics: as the average of many independent random variables as per the central limit theorem, and as the minimum uncertainty state in quantum theory. (It’s actually no coincidence at all, but that must be saved for a different article.) These are two very important contexts, but this is not exhaustive. There are many other contexts in Physics, and there are other distributions besides the Gaussian. And critically, the standard deviation is not a universally good measure of uncertainty. To clarify this, let’s look at an example.

In the above plot we have two normalized Lorentzian or Cauchy distributions, one with a larger half-width (denoted for the Lorentzian by 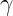
Of course, at this point you may object that the Lorentzian distribution is a pathological example and that this argument is a strawman, and you would be right. After all, the Lorentzian doesn’t even have a well-defined average value, why would we expect it to have a sensible variance? Nonetheless, the Lorentzian is not an obscure and oft-forgotten distribution, especially in quantum optics. On the contrary, it plays a key role in describing the physicist’s second favorite model after the simple harmonic oscillator: the two-level atom.

The Lorentzian appears naturally as the homogenous solution to the Quantum Langevin equation 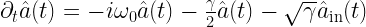

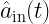
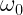
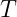
Let’s consider another example–one that will bring us closer to our goal of finding a better measure of uncertainty.
Consider a discretized distribution 
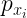

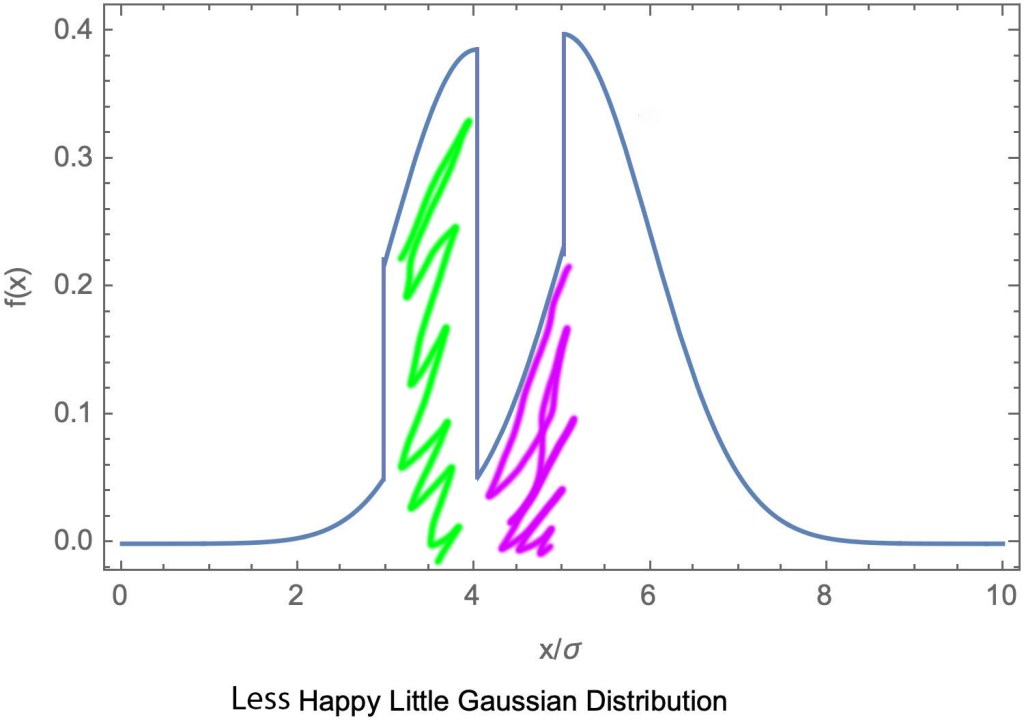
Here we have swapped the two shaded regions of the Gaussian, changing both the mean and also the average distance from the mean, that is, the standard deviation. But notice, the area underneath the curve remains unchanged! If we imagine discretizing this distribution and sampling from it randomly, the probability distribution
To really drive it home, let us consider a very simple example: a distribution consisting of two outcomes for a variable 
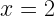
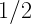


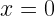
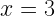

So what do we do? What can we use if not the standard deviation? Is there some other measure of uncertainty with a clear physical meaning that doesn’t suffer from this issue when outcomes are permuted? One that will always gives us a sensible answer for both discrete and continuous probability distributions?
The Solution: Entropic measures of Uncertainty
Enter Claude Shannon, father of information theory.

Given a normalized distribution 


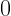
There are many reasons to love the Shannon entropy as a stand-alone quantifier of uncertainty. Unlike the standard deviation which always has the units of the variable it describes, the entropy is unitless. This allows for natural comparisons between different parameters free of reparameterization. And the entropy has a natural interpretation: the number of yes/no questions needed (on average) to determine the value of a parameter (to the resolution determined by the bin size, as we will come back to very shortly). While the interpretation of the entropy as a measure of bits changes if a different base is used for the logarithm, the approach is still the same. And for a parameter that is truly discrete, the Shannon entropy is simply the best measure of uncertainty. In my work in photo detection theory, such a parameter of interest is the number resolution in a photo detector. (Here there is a slight complication; the probability that appears is the conditional posterior probability, which can be calculated through Bayes theorem.)
However, we are not only interested in discrete quantities but also continuous ones. And in these cases, what we want from an uncertainty measure is a quantifier of the resolution provided by an outcome–that is, providing a range of likely values for an arbitrary (read: non-Gaussian) distribution. Here is the procedure for generating such a measure, following closely Białynicki-Birula‘s method, building upon the pioneering work by Helstrom, Białynicki-Birula, and Mycielski.
For a measurement outcome 





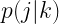

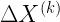
It is simple to see that this definition of uncertainty is independent of the ordering of the bins, but perhaps more surprising is that, in the limit that the bin sizes approach zero 

![[H_x^{(k)} + H_p^{(k)}] > {\rm log}_2(e) - 1 - {\rm log}_2 (\frac{\delta x \delta p}{h})](https://s0.wp.com/latex.php?latex=%5BH_x%5E%7B%28k%29%7D+%2B+H_p%5E%7B%28k%29%7D%5D+%3E+%7B%5Crm+log%7D_2%28e%29+-+1++-+%7B%5Crm+log%7D_2+%28%5Cfrac%7B%5Cdelta+x+%5Cdelta+p%7D%7Bh%7D%29&bg=ffffff&fg=010101&s=2&c=20201002)
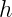



Let’s apply our new uncertainty measures to two of the examples we’ve discussed here. First, let’s revisit our pathological friend the Lorentzian distribution. Now, it is straightforward to calculate the entropic uncertainty, which we find to be 


Let’s also reconsider the two equal-outcome distribution. If we consider these two outcomes to describe two non-overlapping bins of a continuous parameter 
(Here I would like to note that two Gaussians moving away from each other would also have a separation independent entropic uncertainty. Moreover, their variance would be separation independent as well! This is not true for the other distributions discussed above, and is a unique feature of the Gaussian; the reason has to do with the differences between local and global smoothness under scaling transformations, as is outside the scope of this review. All this is to say, the standard deviation really is a good measure of uncertainty for the Gaussian, and credit should be given where it is due!)
This concludes most of what needs to be said here about entropic uncertainty measures; for discrete parameters, the Shannon entropy naturally characterize missing information, and for continuous parameters it is straightforward to generate a resolution measure directly from the Shannon entropy. If you are new to entropic uncertainty measures, hopefully you now feel a little more prepared to understand their usage and necessity. If you’d like to learn more about entropic uncertainty relations and their uses, I highly recommend this wonderful review article. In particular, entropic uncertainties come into play in quantum cryptography (the study of cryptography protocols making use of quantum correlations i.e. quantum key distribution) , quantum metrology, and measurement theory more broadly. Here, there is a natural connection between the entropy and the Fisher information; the Fisher information is a measure of how much of the variance is removed after collecting a single point of data, so that a high-entropy measurement has a low Fisher information.
As a final offering of further reading, if you’re interested in understanding how entropic uncertainty measures can connect the information-theoretic description of a photo detection experiment to industry-standard photo detector figures of merit, this paper (which laid the groundwork for my current understanding, along with my PhD dissertation) should now be fully understandable to you.
I want to end on a more philosophical note discussing entropy, thermodynamics, quantum measurement, and the physical nature of learning.
In quantum theory, a measurement defined by Kraus operators and a POVM is what connects a quantum state to a classical memory register. In other words, it’s how we learn about the quantum world. The quantum states we are trying to learn about are themselves distributions over parameters, and so a Bayesian approach to learning about these distributions is natural (compared to a frequentist’s approach, for instance). In doing quantum measurements, we are trying to update our classical information encoded in bits to accurately describe the quantum distributions in the external world. In the absence of prior knowledge about a quantum state, we start with a high-entropy distribution and move towards a lower and lower entropy distribution as we sample the quantum state. Entropy is the connection between these two distributions, and we can understand its role in our theory as interpolation; the uncertainty of our (classical) distribution is constrained by the entropies associated with the state we are trying to measure and the quantum measurements we perform on that state. (We should also note that inclusion of a classical memory is not necessary for a definition of entropy and a quantum memory can be used as well, as discussed in the aforementioned review article.) We lower the entropy of our distribution by learning. This does not violate the 
Learning requires openness to new information; this holds true as both a statement about human nature and about quantum systems. Open quantum systems are not just a handy way to incorporate the inconvenient effects of decoherence. They are a general framework for understanding information flow in quantum theory, and an essential ingredient to any quantum theory in which learning can occur.
I would like to thank MaryLena Bleile at Southern Methodist University as well as Anupam Mitra at the University of New Mexico’s Center for Quantum Information and Control (CQuIC) for their helpful conversations about entropy and quantum uncertainty. I would also like to offer deep gratitude to Dr. Steven van Enk at the University of Oregon who, during our work together on photo detection theory, introduced me to entropic uncertainty measures and showed me their light.
Dr. Tzula Propp is a postdoctoral researcher at the University of New Mexico’s Center for Quantum Information and Control (CQuIC). Their work in quantum optics and quantum information theory focuses on quantum measurement, quantum amplification, and non-Markovian open quantum systems.
