
Title: Focus beyond quadratic speedups for error-corrected quantum advantage
Authors: Ryan Babbush, Jarrod McClean, Craig Gidney, Sergio Boixo, Hartmut Neven
First Author’s Institution: Google
Status: Pre-print on arXiv
Now is an exciting time for the world of quantum computing. If estimates from researchers at IBM and Google are to be believed, we may have access to a modest fault-tolerant quantum computer with thousands of physical qubits within the next five years. One critical question is whether these devices will offer any runtime advantage over classical computers for practical problems. In this paper by researchers at Google Quantum AI, the authors argue that constant factors from error-correction and device operation may ruin the quantum advantage for anything less than a quartic speedup in the near-term. The cubic case is somewhat ambiguous, but the main message is that quadratic speedups will not be enough unless we make significant improvements to the way we perform error-correction.
Note: In this paper, when they say ‘order-d quantum speedup,’ they mean that there is a classical algorithm solving some problem using 
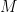
The results of the paper are a little disheartening, because many of the most relevant quantum algorithms for industrial applications offer only quadratic speedups! Examples include database searching with Grover search, some machine learning subroutines, and combinatorial optimization – things any self-respecting tech company would love to improve. We may have to wait for quantum computers that can revolutionize the tech industry, but quantum runtime advantage for algorithms with exponential improvement, like Hamiltonian simulation, could be just around the corner.

Methods: Estimating a quantum speedup
The paper focuses on a specific error-correcting protocol, the surface code, which is widely considered the most practical choice for Google’s architecture. Suppose we want to run an algorithm with an order 
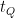
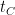

This condition is a bit naive: it assumes the classical algorithm cannot be parallelized.
We can get closer to the real world by incorporating Amdahl’s law for the speedup from parallelizing a classical algorithm. This law states that if 
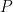

Adding this parallelization speedup, the condition for quantum advantage becomes
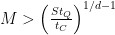
The rest of the paper deals with estimating the parameters 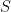
Conclusion: Quadratic Speedups Could Take Hundreds of Years
In the paper, the authors consider two scenarios: 1) a hypothetical ‘lower bound’ based on hardware limitations for the surface code where 

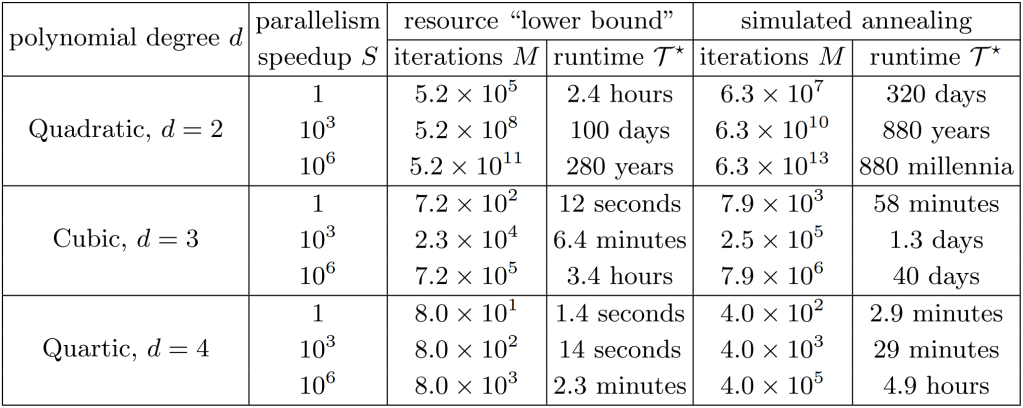
Even in the most generous ‘lower bound’ case, realizing quantum advantage with a quadratic speedup would take several hours of compute time! And, for a more realistic model using simulated annealing, you would need almost a year to see any runtime advantage at all. The situation is much more promising for quartic speedups, where the runtime needed is on the order of minutes and seconds rather than days or years. The moral of the story is that we either need to speed up our surface code protocols significantly or start looking beyond quadratic speedups for practical runtime advantage in the near term.
